
[JSA] PASM:针对hybrid SSD中DNN训练加速的并行度优化存储空间管理策略
PASM: Parallelism Aware Space Management strategy for hybrid SSD towards in-storage DNN training acceleration
作者:肖春华 等人
@ Chongqing University(China)
近存储端的DNN加速器提升了系统整体的性能,但大量的写操作导致了密集的写入放大现象,这对Flash芯片的寿命和性能产生了极大的挑战;目前广泛使用TLC(甚至QLC)来提升flash芯片存储密度的趋势进一步加剧了这个问题。
本文基于SLC-TLC混合粒度型SSD,提出了一种垃圾回收与写入并行的存储空间管理策略来解决这一问题。
论文为什么要做这件事?
在近存储端采用DNN加速器的方案在性能和功耗上都表现不俗,但目前仍然存在以下两个由Flash芯片本身的性质引起的问题:
- NAND flash与DRAM相比寿命短,且各种复杂的物理特征(如页面只能够被写入一次、擦除和写入的粒度不同等等)影响了整体性能。传统FTL中的flash数据管理策略对于具有大量连续写入的近存储DNN训练并不适用。
- 例:DNN 训练需要至少数千次完整的flash芯片写入,大量垃圾回收不可避免的。 传统的并行化数据布局会在垃圾回收过程中造成数据迁移,导致写入放大。 而传统的垃圾回收是基于阈值触发的策略,只有在可用空间逐渐耗尽且低于预设阈值时才会执行,在阈值达到时,持续写入带宽将因为数据迁移和擦除操作显着降低,导致系统的性能急剧下降。
- 高密度的flash芯片(例如TLC/QLC颗粒芯片)逐渐在市场占据主流,相比于SLC芯片其性能和寿命更差,加剧了上述问题。
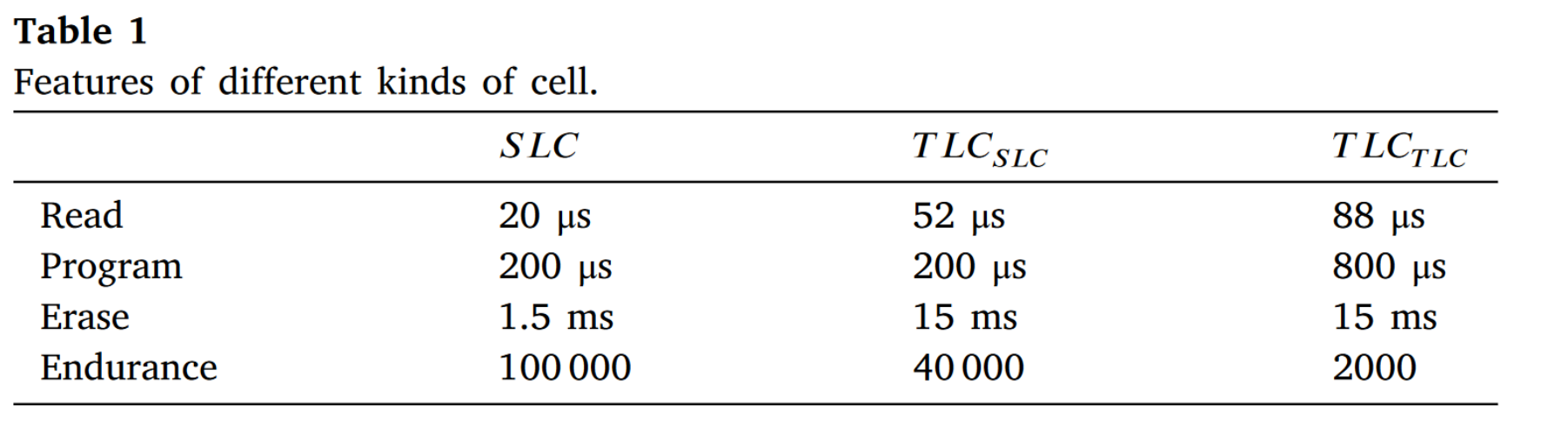
表1 不同的存储单元的在读、写、擦除和寿命上的表现
这个事情之前别人是怎么做的,存在什么问题?
- DNN+ISP:Behemoth利用flash芯片的高带宽和大容量进行语言模型的训练;HyperTune在计算型存储设备上完成了分布式训练等等。然而,DNN+ISP的工作往往局限于使用近存储计算来优化DNN中存在的memory-bound问题,却并没有充分考虑flash芯片的物理特征给DNN训练效率以及flash寿命带来的影响。
- 混合颗粒型SSD(hybrid SSD)是解决高密度flash性能问题的一个有效途径。这种存储利用了flash的dual-mode特性,将flash上的一部分TLC颗粒转换为SLC颗粒,把SLC部分当做flash上的缓存,以利用SLC的高性能和长寿性;运算过程中逐渐地将SLC的数据迁移到TLC部分以保证SLC的容量。

- 图1 混合颗粒型SSD的架构(来源:[19’ICCD] SPA-SSD)
然而,hybrid SSD应用在有大量连续写入的DNN加速方案中仍然有很多问题:
- SLC存储块作为缓存,将数据存入到TLC中这引入了新的数据迁移,会阻碍DNN的连续I/O请求;
- 一旦SLC块用完,并且进行垃圾回收的时候闪存的性能会迅速降低;
- 当SLC块将要用完的时候,为了接受新的写入请求,一些TLC块将不得不转换为SLC块来写入数据,这并没有充分利用SLC的优势。
综上,用hybrid SSD来解决这一问题效果并不好。
该论文解决了什么难点,难点存在的原因是什么,作者是如何发现这些难点的?
下面的探究验证了hybrid SSD在性能和寿命上的存在的问题。
难点1. DNN进行持续写的场景下,混合型SSD的性能损耗

图2 混合型SSD和TLC-SSD在多iteration后的表现
上图反映了用10%SLC-90%TLC和用TLC作为存储系统时的IOPS。当迭代次数增加时,混合颗粒型SSD的的性能迅速下降,甚至降低到TLC存储的效果差不多。原因有以下两点:
- 当SLC块逐渐被消耗的时候,系统只能用TLC来完成I/O请求
- Iteration越大,垃圾回收占用的时间越长,对性能造成了很大的影响。
SLC的效果没有很好的发挥出来。
难点2. DNN持续写的场景下,对flash寿命的挑战
本文在这里粗略计算了一下,在resnet50网络上训练imagenet-2012数据集,只需要13个epochs就可以将2TB的TLC NAND flash用完一遍。
- 传统的垃圾回收机制会在容量到达某一个阈值之后进行。这导致flash始终保持很高的设备占用率,导致在持续写的场景下设备耐久度会下降。这并没有充分发挥混合粒度型存储的潜力。
为了解决以上的问题,作者认为,需要在 DNN 训练过程中并行执行垃圾收集和数据访问,以确保始终有空闲的 SLC 块用于写入请求。
针对以上难点,作者各做了哪些优化,优化背后的思想是什么?
融合PASM的近存储DNN计算

图3 PASM计算架构
DNN加速器:DNN加速器发送数据写入请求时,需要将该数据的寿命包含请求中。一般而言,数据的寿命很难获得,但是在DNN这种数据访问模式非常规律的应用中,数据的寿命可以简单的分析出来。
DNN加速器发出数据写入请求后,数据布局模块(CFP-DL)根据数据生命周期指导数据分配,数据生存周期也记录在映射表中,随着训练过程的进行动态更新。
在训练过程中,垃圾回收模块(LAD-GC)会在后台持续监控闪存阵列中数据的有效性。如果满足预设的擦除条件并且后续 I/O 没有中断,数据回收模块将使用擦除命令将要擦除的块的物理地址发送到FCC。
当达到预设的迭代次数或模型收敛时,训练结束。


表2 DNN训练中各种数据的寿命
CFP-DL:无冲突的、I/O请求与擦除操作可并行的数据布局

图4 数据布局
防止数据迁移
- 问题:当没有足够的SLC块来写入的时候,系统会进行垃圾回收来重新整合数据,最大的问题是写入放大(擦除并重新写入)的过程。重新写入这个过程将占用chip的外部通道,与新写入其他die的I/O请求冲突。
- 根源:数据的寿命不同。传统的FTL将不同寿命的数据放在一起,当寿命短的数据结束使用变为无效的时候,会在寿命长的数据中间留下大量的碎片,这是导致数据迁移的根源。本文的方案试图按照数据的寿命长短归类数据,在垃圾回收的时候只需要做擦除而不需要做写入,防止数据迁移,缓解写入放大的现象。
- 方法:将不同寿命的数据合并放在不同的物理block区域,分为短期数据块、中期数据块和长期数据块。其中短期和中期数据块放在SLC区域,长期数据块放在TLC区域。根据分析文章认为,DNN训练中每层的输出属于短期数据块;产生的梯度和每轮迭代得到的模型参数为中期数据块;检查点和数据集为长期数据块。
I/O与擦除操作并行
- 问题:数据搬运减少,但是对于大量写入的DNN场景下,flash的擦除操作仍然不可避免,仍然影响性能。文章试图进一步对数据布局和垃圾回收机制进行优化,使得垃圾回收与数据访问能够并行执行。
- 根源:擦除操作占用同一个die上的数据通道,I/O与擦除无法并行。
- 方法:本文做了一个权衡,即在同一个chip中,只有一半的die会被物理地址索引选中用来写入,另外的那些die则执行擦除操作。在DNN训练过程中,二者的状态会在某个情况到达时进行交换。这使得这两部分的die能够互不影响,一部分做擦除、一部分做数据访问,虽然一定程度上减半了die级别的并行,但是这保证了SLC能够持续提供很好的效率。
此外,作者还通过模型参数来估算每种block的数量以及关于磨损度平衡的优化,细节不再展开。
效果:将不同生命周期的数据分布到不同种类的物理块中,尽可能避免数据迁移;
通过利用闪存中固有的并行性来实现并行读/编程和擦除操作,从而消除了连续 I/O 请求和垃圾回收之间的冲突,能够在训练期间提供稳定的 I/O 性能。
LAD-GC:数据寿命感知的垃圾回收机制

图5 垃圾回收机制
垃圾回收机制的执行具有严格的时序和顺序,可以防止擦除操作引起的 I/O 阻塞,擦除的时机由数据的生命周期和数据量决定。
第一步:初始权重和数据集被分别保存在中期块和长期块中。上图假定每个chip中只有两个die。我们先选择die0为工作状态来存储输出,die1为空闲状态。
第二步:当DNN训练开始的时候,我们将每层的output和梯度分别写入短期块和中期块。每一个batch反向传播结束之后,我们将输出占据的page状态置为无效。
第三步:在训练的一次iteration中,我们反复进行以上过程,直到垃圾回收机制发现在工作die的短期块中有一个完全无效的数据块的时候,如果有则直接执行垃圾回收机制,并交换die0和die1的工作状态。
第四步:第二次迭代开始时,上一次迭代产生的梯度数据已被用于更新权重,变得无效。在 Die 1 有无效的短期块之前,垃圾回收机制会检测 Die 0 中是否存在无效的中期块,如果有,则擦除 Die 0 中的无效中期块。
需要注意的是第三阶段的交换时机很重要。如果原die中还有一些需要读取的数据,当这个die被设置为GC状态时,读取请求的服务会被阻塞。因此,对于每个 die,垃圾回收机制只在 BP 结束并完成标记数据的读取请求后寻找一个完全无效的短期块。通过这种方式,可以确保不再有读取请求被阻塞。
效果:垃圾回收机制通过感知数据生命周期,在不干扰连续 I/O 请求的情况下执行擦除操作,能够及时有效地回收无效块,以保证 SLC 的高耐久性可以得到连续不断的利用。
实验结果
仿真平台
Flash Controller仿真:HybridSim
DNN加速器仿真:ScaleSim
将ScaleSim的输出接到HybridSim的输入上去。
参数设置:

数据集:Imagenet-2012
模型:resnet-50
验证CFP-DL和LAD-GC的有效性
Baseline: SPA-SSD是一种hybrid SSD实现方案,利用SLC部分作为缓存。
SPA-SSD-h是SPA-SSD只用一半的die,但是全部都采用SLC作为存储颗粒的、具有无限容量的理想方案,即其不需要做垃圾回收。作者用这个方案来说明PASM与理想方案之间的差距。
- 并行数据布局的效果

iteration增加时,相比于SPA-SSD来说,PASM的写入平均响应时间更为稳定,读出的平均响应时间好像略有增加。这主要是因为并行度降低了。
PASM与SPA-SSD-h相近,说明数据布局可以很大程度地减少垃圾回收引起的冲突,稳定地提供I/O性能。
- 垃圾回收机制的效果

iteration非常高的时候,SPA-SSD的擦除操作陡然上升。
整体来看,PASM中大部分擦除都是与访问并行的,充分利用了并行性。
效果
- IOPS

SPA-SSD的性能在iteration到达100以上时,与传统的SSD没什么差别了。但是PASM则一直表现稳定。
- SLC擦除次数

当iteration很高的时候,SPA-SSD和TLC-only SSD的擦除次数是PASM的6.6倍,这说明PASM可以延长寿命6倍左右。
自己的思考
本文的主要两个创新点对于具有大量数据写入的应用有较好的借鉴意义。
但是文中一些设计考虑属于比较启发式的,感觉一些机制没有特别扎实的论证,比如垃圾回收机制;实验探究比较少。


- 本文作者: Zhang Xinmiao
- 本文链接: https://recoderchris.github.io/2022/06/15/pasm/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!