
SmartSAGE: Training Large-scale Graph Neural Networks using In-Storage Processing Architectures
作者:Yunjae Lee等人, lead by Minsoo Rhu
@ KAIST(Korea)
既要提升图神经网络(GNN)训练扩展性,又要保证系统整体的性能。
主要做法是通过采用SSD保存原始图数据,提升了GNN训练的扩展性;
通过用近存储计算的方法完成GNN的采样步骤,保证了方案的处理性能。
背景
图神经网络训练
图神经网络的训练主要有选择目标节点、目标节点邻居采样、特征查找,最终将邻居节点的特征通过多层感知机实现训练,以得到目标节点或边的嵌入向量。
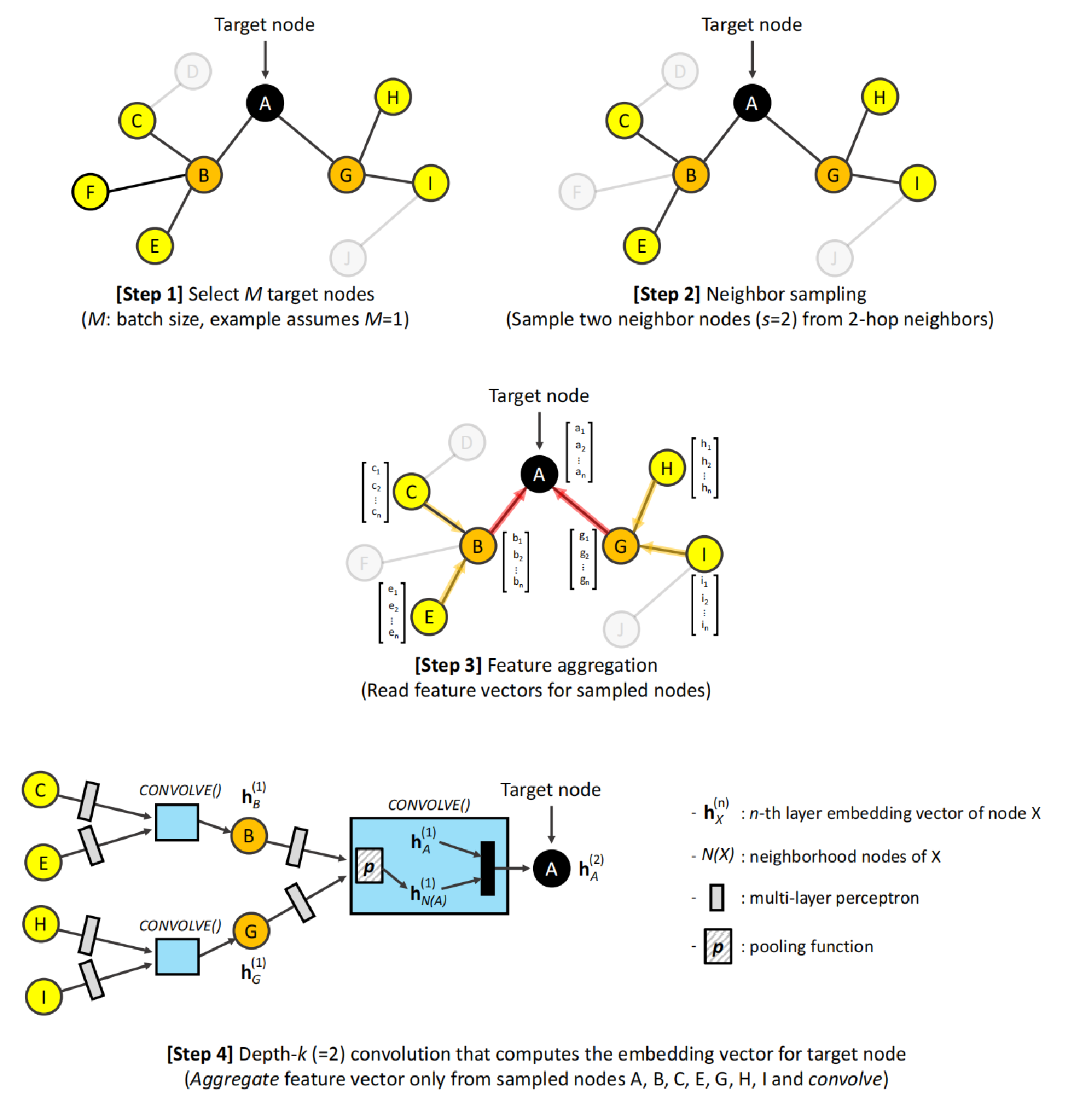
架构导致的瓶颈问题
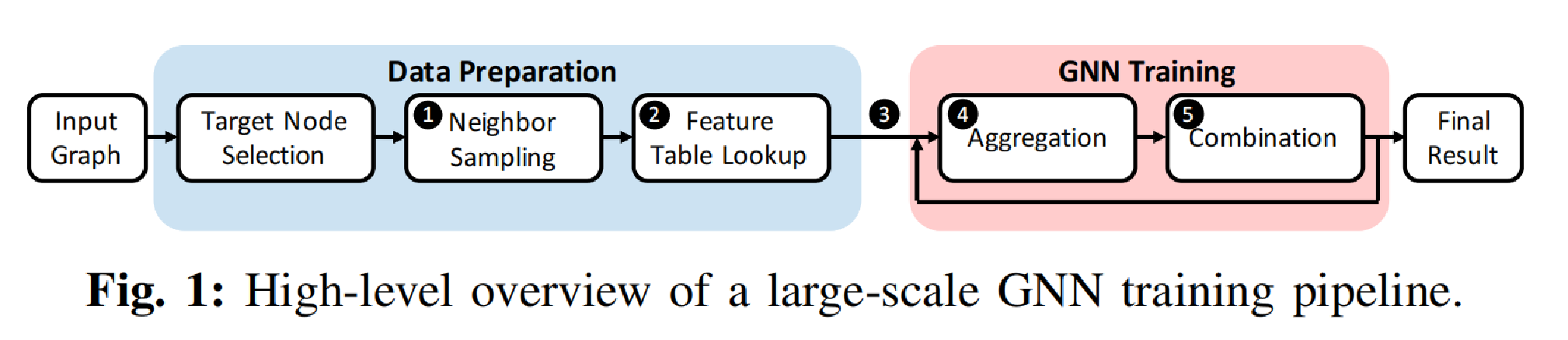
实际训练流程往往是按照以上这张图的步骤来进行的,主要分为两个大的环节:数据准备和GNN训练。而这两个环节有完全不同的计算特征:在数据准备阶段中的邻居采样是在整个大图上进行的,且访问不规律;而后面GNN训练阶段的特征聚合以及GNN训练是在前面采样出来的一个很小的子图上完成的,其计算特征固定,可用GPU进行加速。

传统的训练流程和架构的映射如图a所示。考虑到访问的不规则,图神经网络框架(e.g. PyG,DGL)往往把采样和邻居特征查询这两个步骤放在内存中完成的,然后再将查出来的子图的特征通过PCIe传送到GPU的memory上进行计算。
这样做的瓶颈在于:采样这一步的扩展性差。主要问题是采样是针对整个大图的,对于大型的图内存很有可能放不下,设计人员不得不限制图的大小,那么这等于限制了图神经网络表达能力,进而限制网络的实际应用效果。
要解决的基本问题

一个自然的想法是上图所示的架构:采用SSD作为存储数据的主体,DRAM作为缓存来存正在计算的数据或者缓存一些局部性高的数据,采样仍然在CPU上完成。然而一个很明显的问题在于:SSD的吞吐量显然没有DRAM高,对性能会产生影响。由此产生的一些疑问是:这样做是否会极大程度的影响整体性能?有什么方法可以进一步优化此架构下的性能表现?
下面的motivation实验,文章主要展现了用DRAM和SSD存放图数据进行图神经网络训练时,系统的一些特征。
论文为什么要做这个事情?
端到端性能分析
作者先分析了DRAM和用SSD来存放数据时,进行GNN训练时一个端到端的时间模型。如下图所示:

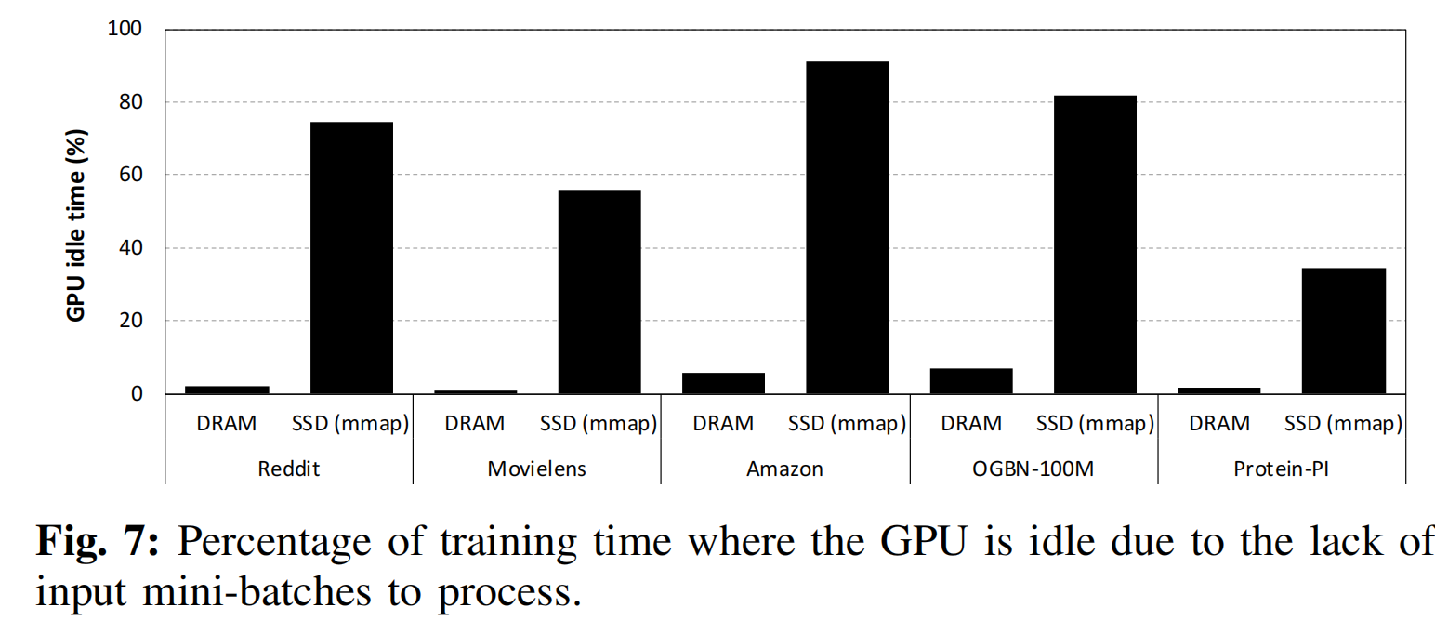
图a展示了in-memory的运行模型,b则是采用ssd作存储设备的运行模型。实际运行中,训练和采样是并行的。可以看到,由于SSD的带宽低于DRAM,CPU上的数据准备步骤会引发高延时,以至于让GPU陷入大量的空闲等待,产生对计算资源的浪费。
下面文章剖析了为什么会出现这种现象:
当用DRAM存图数据时
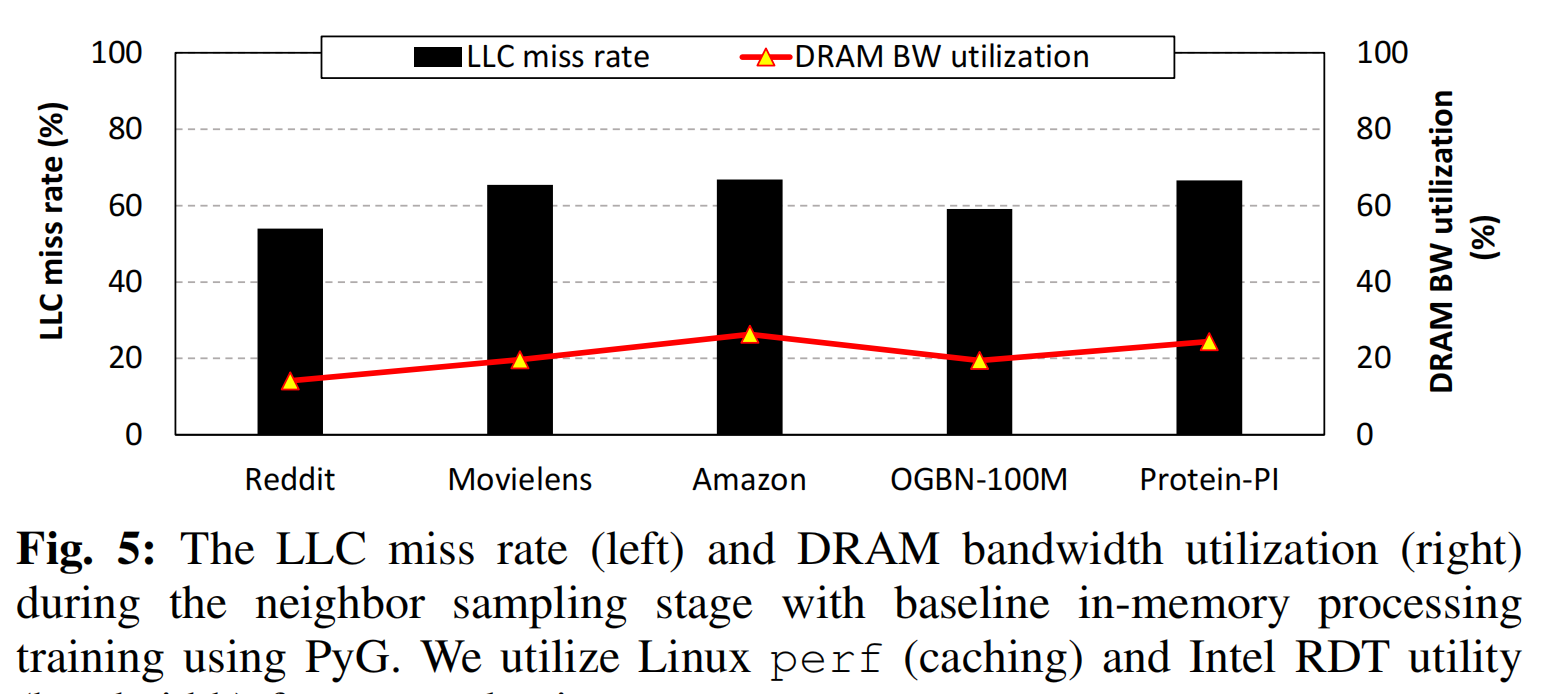
为了更好的理解采样过程的特点,对传统方案,文章测试了系统的cache miss率和带宽利用率两个参数,探究计算延时是由什么导致的。
文章发现在in-memory时cache命中率非常低,且内存带宽的利用率也非常低。从算法角度很好解释。而进一步,这说明:采样操作的性能主要被纯的memory latency限制,而不是被throughput限制。这一点将指导基于SSD的方案设计。
SSD存图数据
文章首先给出了全文的一个baseline:即将图数据保存在SSD上,并在主机上进行采样操作;访问数据时采用mmap对图数据集文件在用户空间上做地址映射,这样能够利用操作系统的page cache进行缓存,以提升局部性。
文章下面对这个方案的性能进行了仔细分析。下图展示了in-memory和baseline两个方案训练延时的breakdown以及端到端计算延时的倍数增长:
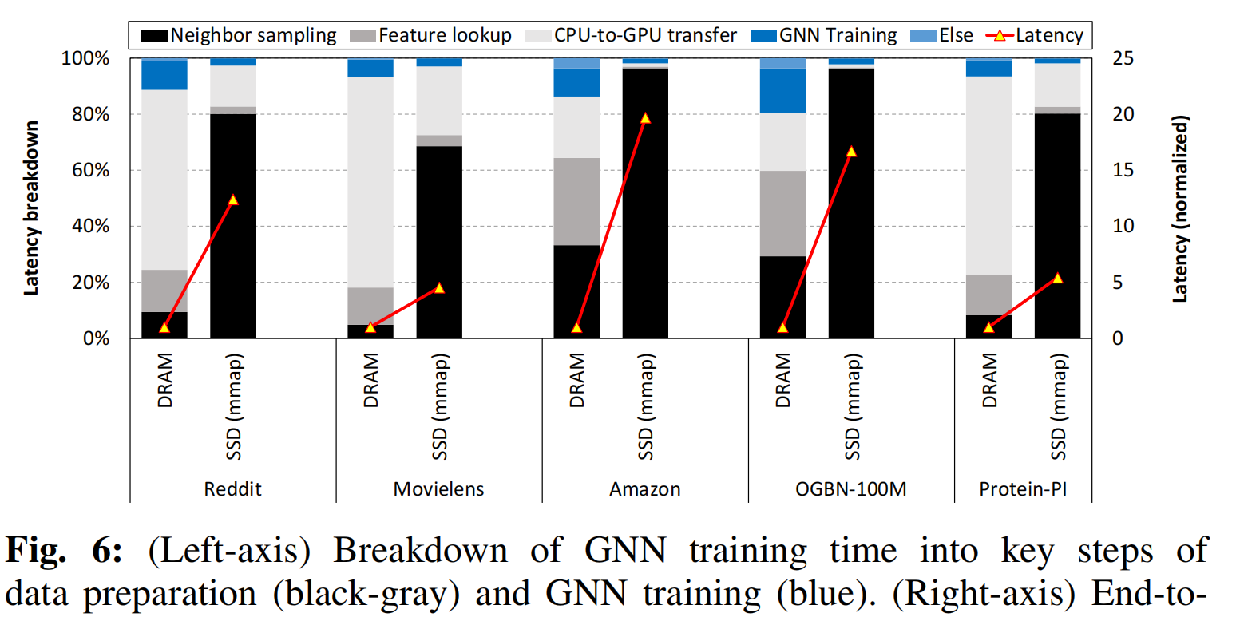
可以看出,将存储主体从DRAM改为SSD之后,整个延时的开销主体变为了采样这一步,并且延时有了平均9.8倍的增加。原因是sample的局部性非常差,操作系统中页面缓存的命中率很低,用mmap非但不能从局部性获得好处,反而会引起频繁的缺页中断和操作系统的用户-内核态切换。因此,图采样成为了训练过程中的瓶颈问题,最终将引发GPU计算资源的空闲。如下图所示:
文章采用近存储计算的方法来解决这个问题,旨在弥补DRAM和SSD方案之间巨大的性能差异。
该论文解决了什么难点,难点存在的原因是什么,作者是如何发现这些难点的?
文章要解决的主要难点是:既要用SSD来打破内存容量的限制,又要用近存储计算的手段来缩近SSD与DRAM之间巨大的性能差距。
软硬件协同:
第一:硬件上,用近存储计算的手段将随机采样的计算的过程卸载进SSD里面。将采样这一算法步骤部署在存储器的固件中,其目标是提升子图生成过程中的有效吞吐量,减少无关数据的转移;
第二:软件上,摒弃了之前以优化局部性为导向的方案,设计了以优化延时为导向的运行时系统和主机驱动栈。不再采用操作系统的页缓存,使用Linux的直接I/O命令并设计了用户空间的数据缓存。这使得运行时系统可以直接将数据读取到缓存上,减少了查询软件栈的开销;同时合并了多条NVMe指令,减少了多条I/O指令调用的开销。
针对以上难点,作者各做了哪些优化,优化背后的思想是什么?
硬件上:ISP
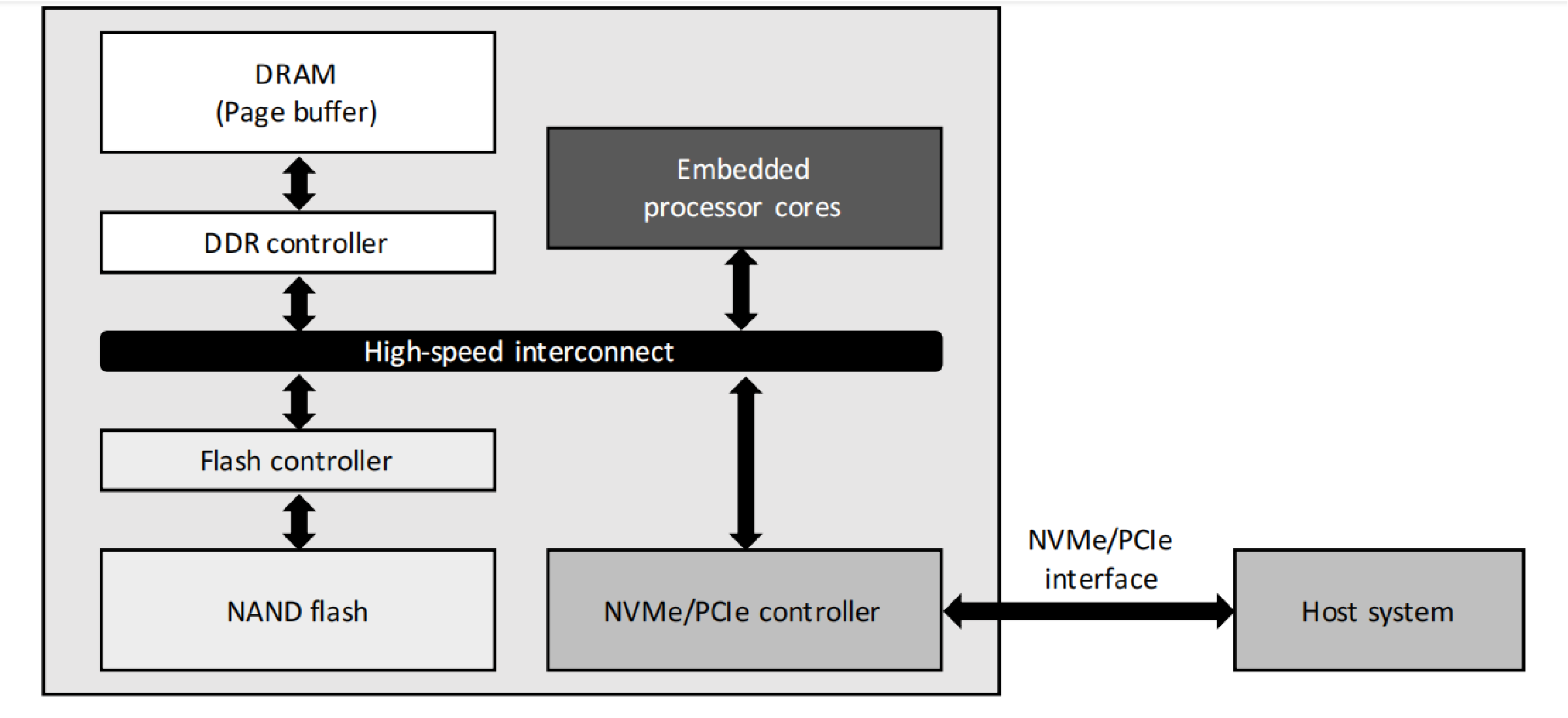
作者通过修改SSD控制器中的固件代码,实现了对采样(sampling)过程的近存储计算。
Why not FPGA-based but firmware-based?
第一、采样这个过程的计算的密度很低。主要复杂度在于随机数据的查询;没必要用FPGA。
第二、用FPGA需要额外的数据转移:即从SSD通过PCIe switch到FPGA,再从FPGA到主机端CPU的过程,本身数据转移的延迟高,用FPGA是否能获得性能提升有待推敲。文章在实验阶段也验证了这一点。

而计算密度低的采样过程刚好与羸弱的嵌入式处理器性能匹配。
近存储计算设计

图a是baseline的方案。当我们要在这两个Batch,4个目标节点上完成采样的时候,我们首先要将这4个目标节点的邻居节点的地址找到,然后依次发送以block为级别的I/O请求,把数据全部从SSD传送到CPU一侧,然后在主机上完成采样。

图b是文章建立了近存储计算模块之后的,我们可以直接在存储端完成采样,并把采样后的子图发送给主机一侧。
这样做提升了系统的有效吞吐量,并且由于发送给DRAM的只有采样出的很小的子图,这也可以合理利用宝贵的带宽。

主要两个模块:近存储控制模块和子图生成器;主要流程:
- 主机端发送 【子图生成】 的I/O命令,SSD接收(1);
- 存储端通过DMA从主机端获取目标节点等关键信息(2),子图生成模块将此解码并获得目标节点的邻居节点所在的物理页面号(3);
- 发送物理页面的读取命令给底层的读取队列(4);
- 读到物理页面信息,先缓存在SSD的DRAM里面(5),子图生成器模块对数据进行采样,并将获得的子图存放在子图缓存区中等待发送;(6)
- 计算完毕后,将采样得到的子图发送回主机端。(7)
软件上:以延迟优化为导向的运行时系统和主机驱动栈
以延时优化为导向是针对于“以访存局部性优化为导向”这一方案提出的。
第一,“以访存局部性为导向”实际上就是baseline系统中基于memory-map的SSD数据访问,采用操作系统页面缓存来优化局部性的这种方案。这种方案在图采样应用上,对于减少I/O访问时间几乎没有什么用,因为随机采样有很差的局部性,反而由于页缓存的存在,在读取数据的时候需要一些复杂的缺页中断处理等操作。
第二,baseline的方案需要大量的I/O请求,这是因为每个I/O请求对应的是以chunk为单位的数据,而很多数据都是无用的,这又增加了另一个层面的计算延迟,即每个以chunk为单位的请求穿过主机驱动栈的时候,都需要经历从用户空间到核空间的双向转换。
下面的优化主要针对运行时系统和主机驱动栈,以延时优化为导向进行设计。主要两个方面:越过软件栈完成直接I/O;同batch的I/O请求的合并。

直接I/O
用linux的直接I/O特征,使得文件写和读操作可以直接从用户空间的应用访问到存储设备,不需要经过操作系统的页面缓存,也不需要从用户空间到核空间的双向转换。
I/O命令合并
对于同一批采样,调用SSD做计算的命令合并在一条I/O指令中。系统预先将计算需要的参数保存在本地上;调用唤醒近存储计算模块的I/O指令时,通过DMA将参数全部发送过去,近存储端再进行计算。整个batch只需要一条命令,这样大大减少了调用I/O的命令的条数,缩减了主机驱动栈的开销。
实验结果
实验设定
主机端:CPU-GPU系统,包含Intel Xeon Gold 6242 CPU with 192GB of DRAM and NVIDIA’s Tesla T4 GPU
CSD平台:Cosmos+ OpenSSD
对比对象:
- baseline方案;
- 基于FPGA的CSD:Samsung-Xilinx’s SmartSSD
- in-memory方案:用intel optane PMEM,提供768GB的空间。
Mini-batch大小:1024
单线程性能对比

单线程性能对比:
software-only:1.5x
hw-sw: 6.6x to software-only

命令合并的效果如上图所示,横坐标是命令合并的大小,纵坐标是性能表现(越高越好)。
多线程性能对比

**software-only:**3x
Hw-sw: 1.3-1.4x to software-only

上图显示,当线程数逐渐增多时,加速比降低。这是因为存储端的算力限制导致的,多个线程同时做计算会挑战存储端的计算能力。下面的一段论述描述了如果采用NGD的Newport上的嵌入式处理器(四个ARMv7 M7运行固件管理程序,双核ARM v8 Cortex A53专门用来近存储计算),效果将会更好。

Latency Breakdown对比

这里添加了一个smartsage(oracle),文章在这里估算了如果采用Newport系统进行近存储计算的表现。
首先,sampling这个瓶颈问题被很大程度上缓解了;
其次,这里也估算了用DRAM做存储的方案,相比于DRAM的性能只差60%,但DRAM方案不现实;
oracle方案相比于傲腾(PMEM)只是1.2倍的延时开销,但是价格大大降低了。
Why not FPGA?

相比起来,FPGA将大量的时间用在了SSD到FPGA之间的数据传递上,整体的时间开销可能比sw版本还要大。
参数敏感性

采样率升高的时候,系统加速效果会逐渐减弱。(算力限制、子图变大导致从SSD到主机的数据传输量变大)
自己的思考
- 优点:动机实验做的很详细;实验充分;把一些问题写的很清楚(为什么不用FPGA、构想了如果有更好的处理性能效果将会怎样)
- 创新性?:硬件部分本质上是对随机采样过程做了近存储计算,且每个batch的计算量是一个常数,从应用的角度来说对计算总量有很强的限制。相比于我们做的random walk计算量要小的多(random walk是随着图的尺寸扩展计算量在增大的,且在random walk实际的调度率接近100%);软件部分,对软件栈的优化比较简单,命令合并在设计中也显得很自然(我们也想到了,但感觉没必要着重写),整体来说好像新意不是很足。。。但是结合GNN训练的背景,文章的写作值得学习。
- 忽略了嵌入处理器的性能问题:文章对算力的问题没有额外的讨论,通过采样这一个对算力依赖非常小的应用达到了很好的实际效果;但是从最后的参数敏感度实验可以看出,采样率变高的系统的加速效果是逐渐减弱的。


- 本文作者: Zhang Xinmiao
- 本文链接: https://recoderchris.github.io/2022/05/20/smartsage/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!